知识点补充
SQL的思想
面向集合的思想
SQL 是为查询和管理关系型数据库中的数据而专门设计的一种标准语言。我们通常认为的关系型是说的数据库中表与表的关系,这个理解是有问题的,这里的关系其实是数学术语上的关系。
为什么这么说?
因为关系型数据库是以关系模型为基础,而关系模型是以集合论和谓词逻辑两大数学理论为依据的。集合论中,关系是集合的一种表示。在关系模型中,关系是相关信息的一个集合,反映到数据库中就是一张表。
我们知道集合是不关心顺序的。表作为一个集合,它本身并没有顺序的概念。在很久之前有人问过,我按顺序插入id=1,2,3的记录,为什么查处来时和插入的顺序不一致。很多人都有这样的认为,就是从表选取记录时,记录是按插入顺序或主键的大小顺序返回的。在 SQL 评审中也经常遇到不带 ORDERBY 的 LIMIT 语句。
这么写实际上是有问题的,不带ORDER BY子句的查询只表示从集合中查询数据,返回的结果是不确定的,之所以结果看起来对的,是因为 MySQL 访问数据的方式和你的需求恰巧一致了,表上索引或数据的变化都可能会影响到你的结果。因此要牢记不要为表中的行假定任何特定的顺序,确定需要按某个顺序取数时显式的加上 ORDER BY 。
很多人都是先有面向过程和面向对象的对象的编程经验后开始 SQL 编程的,这往往限制了对 SQL 问题的思考。
SQL 和传统编程语言最大的区别是它以关系模型和集合论为背景。在 SQL 编程中最能体现面向过程和面向集合区别的就是对游标的使用,面向过程的编程同样体现在使用中对子查询、派生表、以及临时表的过多依赖。许多人的编程经验是把一个任务细分成许多小任务,而后按一定的顺序来实现它们或先把需要的数据存储在各个临时表或先包含在派生表里再做关联处理。但如果按这种方式处理 SQL 编程,可能只会得到平庸的结果。
这类实现往往是代码很长,很难维护,欠缺灵活性,而最大问题是由于相对固化的处理逻辑限制了优化器的优化空间,大多数情况下这类面向过程的实现在性能上都远不如面向集合的实现。编写高效的 SQL 需要我们跳出原有面向过程的思维方式,换一种思维方式去思考问题。可以总结为:解决 SQL 问题时要关注的是获取“什么”,而不是“如何”去获取。 SQL 是一门注重思想而非技巧的语言。
https://www.cnblogs.com/Alight/p/3649412.html
SQL 语句的执行顺序
有些情况下 Select 语句没有加 “ Order By ”,返回的数据是不确定的
这种问题碰到不止几次了。追根寻底, Select 语句如果不加 “ Order By ”, MySQL 会怎么排序呢?
- 不能依赖 MySQL 的默认排序
- 如果你想排序,总是加上 Order By
- GROUP BY 强加了 Order By (这与标准语法冲突,如果要避免,请使用 ORDER BY NULL )这里我有疑问,到底强加了何种 Order by
对于 MyISAM 表
MySQL Select 默认排序是按照物理存储顺序显示的。(不进行额外排序).也就是说SELECT * FROM tabl – 会产生“表扫描”。如果表没有删除、替换、更新操作,记录会显示为插入的顺序。
对于 InnoDB 表
同样的情况,会按主键的顺序排列。再次强调,这只是潜规则(artifact of the underlying implementation:怎么翻译?),不靠谱的。
理解与推测
“ Select ” 不加 “ Order by ”时, MySQL 会尝试以尽可能快的方法( MySQL 实际的方法不见得快)返回数据。由于访问主键、索引大多数情况会快一些(在 Cache 里)所以返回的数据有可能以主键、索引的顺序输出,
这里并不会真的进行排序,主要是由于主键、索引本身就是排序放到内存的,所以连续输出时可能是某种序列。
在一些情况下消耗硬盘寻道时间最短的数据会先返回。如果只查询单个表,在特殊的情况下是有规律的。
最后总结:
“Order By 是要加的”
https://blog.csdn.net/caomiao2006/article/details/52144949
SQL 的理论其实是集合论,常见的类似求数据的交集、并集、差集都可以使用集合的思维来求解。集合中的行之间没有预先定义的顺序,它只是成员的一种逻辑组合,成员之间的顺序无关紧要。如下图,每一个括号里的内容就是一条记录,在没排序前,他们都是随机分布在集合中。
Student(ID,Name,Age)

但是对于带有排序作用的 ORDER BY 子句的查询,它返回的是一个对象,其中的行按特定的顺序组织在一起,我们把这种对象称为游标。
如下图,经过对 Student 表的 ID 进行 ORDER BY 排序后, Student 表变成了有序对象,也就是我们上面说的游标。
Student(ID,Name,Age)

二、ORDER BY 子句是唯一能重用列别名的一步
这里涉及 SQL 语句的语法顺序和执行顺序了,我们常见的 SQL 语法顺序如下:
1 | SELECT |
而数据库引擎在执行 SQL 语句并不是从 SELECT 开始执行,而是从 FROM 开始,具体执行顺序如下(关键字前面的数字代表 SQL 执行的顺序步骤):
1 | (8)SELECT (9)DISTINCT (11)<Top Num> <select list> |
从上面可以看到 SELECT 在 HAVING 后才开始执行,这个时候 SELECT 后面列的别名只对后续的步骤生效,而对 SELECT 前面的步骤是无效的。所以如果你在 WHERE , GROUP BY ,或 HAVING 后面使用列的别名均会报错。
我们举例测试一下。
示例表 Customers 结构及数据如下:
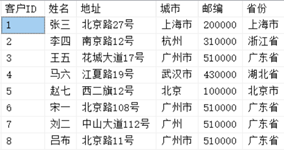
1、 WHERE 后面不使用别名的情况
1 | SELECT |
结果如下:
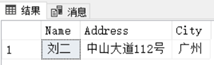
2、 WHERE 后面使用列别名的情况
1 | SELECT |
执行结果如下:

从返回的消息中我们可以看到,重命名后的 City 并不能被 WHERE 识别,所以才会报“列名’ City ‘无效”的提示。
其他关键字大家也可以使用上述方法进行测试,下面我们测试 GROUP BY 和 HAVING 后面使用列别名的情况。
3、测试 GROUP BY 后使用列别名
1 | SELECT |
结果如下:
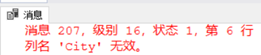
4、测试 HAVING 后使用列别名
1 | SELECT |
5、测试 ORDER BY 后面使用列别名
1 | SELECT |
结果如下:
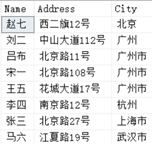
从上面的几个测试示例的结果中,可以得出我们的结论是正确的: ORDER BY 子句是唯一能重用列别名的一步。
三、谨慎使用 ORDER BY 后面接数字的方式来进行排序
有些小伙伴为了图省事,喜欢在 ORDER BY 后面写数字,具体示例如下:
1 | SELECT |
结果如下:

这样写的结果,针对当前的查询是正确没有问题的, ORDER BY 后面的数字1,2,3分别代表 SELECT 后面的第1,第2,第3个字段(也就是 Name, Address , City)。
可是当查询的列发生改变,忘了修改 ORDER BY 列表。特别是当查询语句很长时,要找到 ORDER BY 与 SELECT 列表中的哪个列相对应会非常困难。
例如:
1 | SELECT |
由于增加了一列“客户 ID ”,原本的题意还是对 Name , Address , City 排序,但是因为使用了 ORDER BY 加数字,排序后的结果如下:
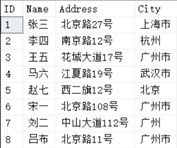
得到的结果并不是我们想要的,所以请慎用 ORDER BY 加数字,尽量使用 ORDER BY 加列名或列别名。
四、表达式不能使用 ORDER BY 排序
表表达式包括视图,内联表值函数,派生表(子查询)和公用表表达式( CTE )。
例如下面的视图是无效的
1 | CREATE VIEW V_Customers AS |
结果如下:

这个错误是不是很熟悉?因为很多小伙伴经常喜欢在视图或子查询里面加 ORDER BY ,然后一执行就会报这个错。
根本原因不敢妄加断定,因为搜寻了很多文献资料也没给出一个具体的说法。
这里猜测是因为视图,内联表值函数,派生表(子查询)和公用表表达式( CTE )等返回的结果还需要进一步的去使用,加了 ORDER BY 进行排序是多此一举,反而会浪费系统资源。所以数据库的开发者不希望大家使用这样不规范操作。
所以下次就不要在表表达式里添加 ORDER BY 了。
五、 T-SQL 中表表达式加了 TOP 可以使用 ORDER BY
我们从第四点的报错信息中可以看到:在另外还指定了 TOP 、 OFFSET 或 FOR XML 是可以使用 ORDER BY 的。

这又是为什么呢?
我们还是先举个栗子给大家看一下
1 | SELECT |
因为 T-SQL 中带有 ORDER BY 的表表达式加了 TOP 后返回的是一个没有固定顺序的表。因此,在这种情况下, ORDER BY 子句只是为 TOP 选项定义逻辑顺序,就是下面这个逻辑子句
1 | SELECT TOP 3 * |
结果如下:

而不保证结果集的排列顺序,因为表表达式外面至少还有一层才是我们最终需要的结果集。
这里的 ORDER BY 只对当前的子查询生效,到了主查询是不起作用的。必须在主查询末尾继续添加一个 ORDER BY 子句才能对结果集生效,就像我们例子中写的那样。
除非逻辑要求,一般情况下并不推荐大家这样巧妙的避开子查询中不能使用 ORDER BY 的限制。
https://database.51cto.com/art/201912/608333.htm
SQL 常用关键字
select * :
返回所有记录
limit N :
返回 N 条记录
offset M :
跳过 M 条记录, 默认 M=0, 单独使用似乎不起作用
limit N,M :
相当于 limit M offset N , 从第 N 条记录开始, 返回 M 条记录
ORDER BY :
释:该关键字用于对结果集按照一列或者多个列进行排序
该关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以在 SQL 后添加 DESC 关键字
SELECT DISTINCT :
在表中,一个列可能会包含多个重复值,有时也许希望仅仅列出不同( distinct )的值。
DISTINCT 关键词用于返回唯一不同的值。
使用该关键字必须指定
例:SELECT DISTINCT <column_name> FROM <table_name>
SQL Aggregate函数 :
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
• AVG() - 返回平均值
• COUNT() - 返回行数
• FIRST() - 返回第一个记录的值
• LAST() - 返回最后一个记录的值
• MAX() - 返回最大值
• MIN() - 返回最小值
• SUM() - 返回总和
WHERE :
子句用于提取那些满足指定条件的记录。
例:
1 | SELECT <column_name>,<column_name> |
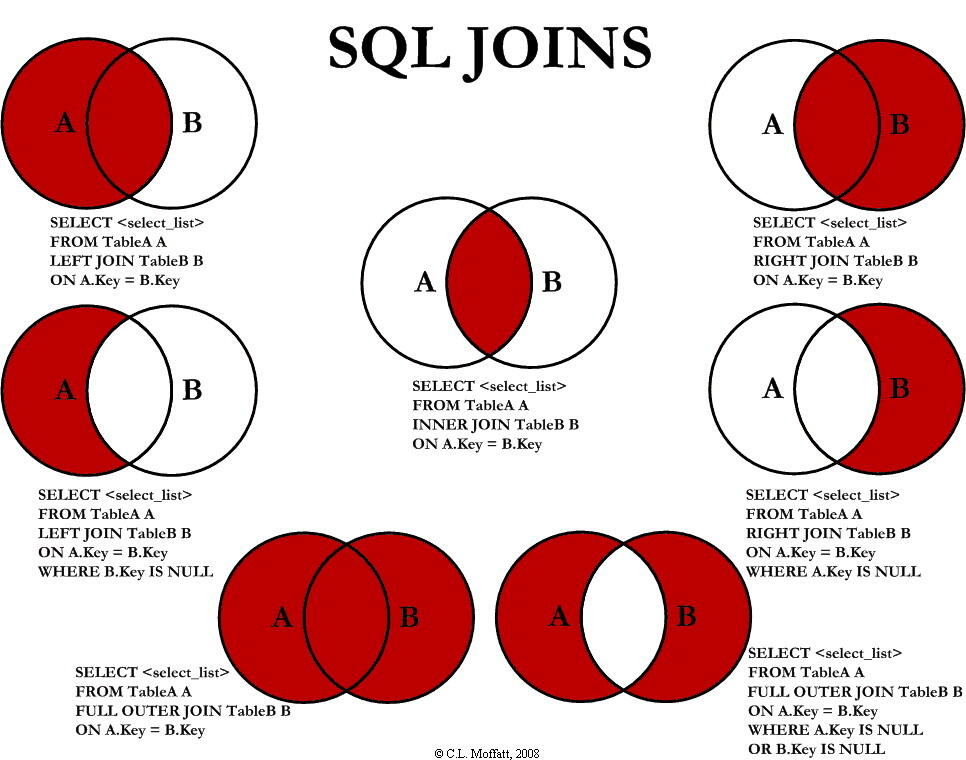
https://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins
SQL1 查找最晚入职员工
https://www.nowcoder.com/practice/218ae58dfdcd4af195fff264e062138f
题解:
最晚入职的员工可能会有多人
我们使用集合的思想解题就是:查出整张表与整表的 hire_date 字段的最大值的交集
即:
1 | select * from employees |
SQL2 查找入职员工时间排名倒数第三的员工所有信息
https://www.nowcoder.com/practice/ec1ca44c62c14ceb990c3c40def1ec6c
题解
查入职员工表,通过where过滤时间,所以还要使用子查询查出时间排名倒数第三的员工;但是时间倒数第三的员工可能不止一个,通过 DISTINCT 关键字过滤掉重复出现的时间。
1 | SELECT * FROM employees |
SQL3 查找当前薪水详情以及部门编号 dept_no
https://www.nowcoder.com/practice/c63c5b54d86e4c6d880e4834bfd70c3b
题解
入职时间相同的员工可能有多人